Retrieval Augmented Generation (RAG)
Overview
Retrieval Augmented Generation (RAG) is a pivotal feature within SeaChat, enhancing data retrieval and augmenting the accuracy of interactions with the AI agent. It provides you with the ability to change settings for Query Pattern, Search Method, and Knowledge Base Retrieval Count. By experimenting with these settings, you can customize how your AI agent interacts with the knowledge base efficiently.
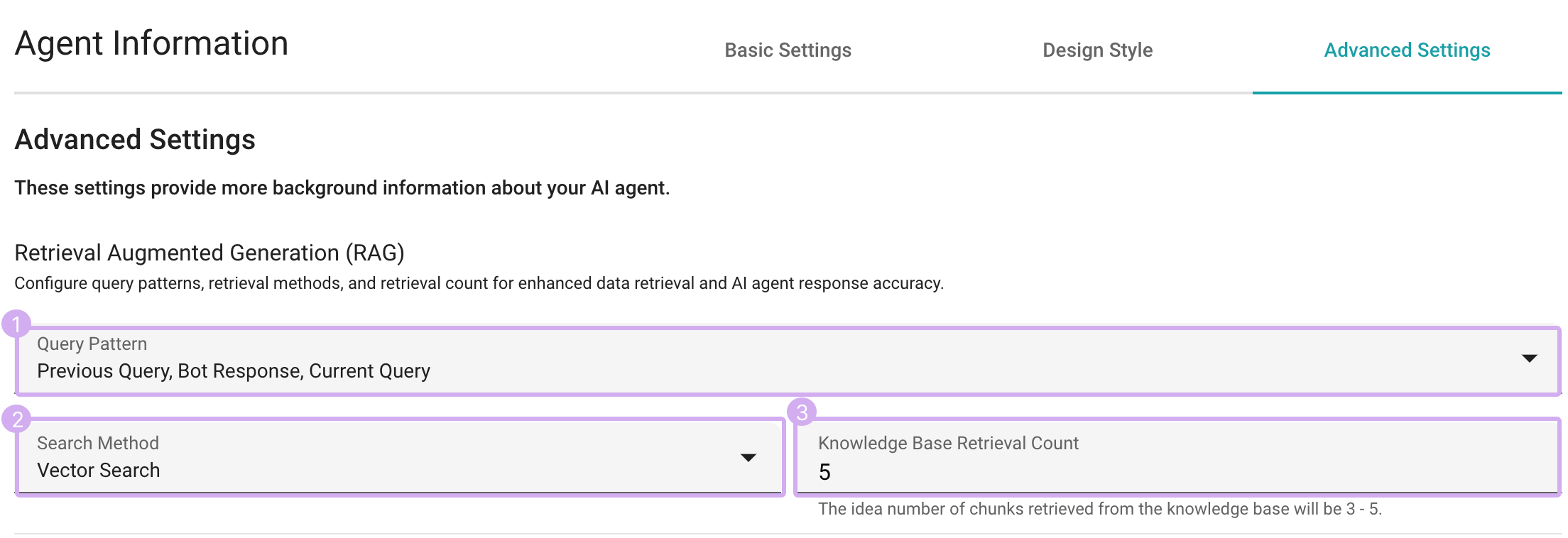
RAG Settings in SeaChat
Query Pattern
Whether you require comprehensive context, focused engagement, or quick, precise responses, SeaChat’s flexible query patterns for querying the knowledge base ensure an optimized chat experience tailored to your preferences.
The following is an example conversation between a customer and a parking lot FAQ AI agent with information of more than hundreds of parking lots in the knowledge base:
👨 (Previous Query): Is there a parking lot near the Seattle Space Needle?
🤖️ (Bot Response): Yes, you can park at the ABC Parking Lot on 123rd Ave NE. It has 50 parking spots. The parking fee starts at $10 per hour, with a daily maximum of $60.
👨 (Current Query): I will be working near there. Can I rent a parking spot monthly?
Previous Query → Bot Response → Current Query
Offers comprehensive context by incorporating the last three turns of the conversation. In this case, the complete conversation (Previous Query + Bot Response + Current Query) is used to query the knowledge base and to generate the AI agent’s next response for Current Query.
Previous Query → Current Query
Focuses more heavily on the user’s requests and is not influenced by the AI agent’s response. It includes the last two user inputs (Previous User Query and Current User Query) to query the knowledge base and to generate the AI agent’s next response.
Current Query
Provides a succinct approach, considering only the user’s latest input, i.e. Current User Query, for the AI agent’s next response. This is ideal for one-turn dialogues or cases where users frequently switch topics. However, it may miss important context when discussing the same topic over multiple turns.
Search Method
You can optimize knowledge base search by choosing from distinct knowledge base search methods:
Keyword Search
Matches user’s provided keywords against the knowledge base to deliver relevant results. This works well when you have unique tokens such as product names, locations, IDs, etc. but may miss cases where the user doesn’t say the exact keyword (for example, they use a synonym or a different language than the KB document).
Vector Search
Utilizes the capabilities of text embedding to enhance the retrieval of relevant information. Vector search can work well across languages and retrieve similar documents even if they don’t have matching keywords. However, it may struggle with rare tokens such as product names, locations, or IDs.
Hybrid Search
Integrates both Keyword and Vector Search methods to optimize information retrieval.
Knowledge Base Retrieval Count
Changing Knowledge Base Retrieval Count allows you to specify the number of KB documents(chunks) to retrieve, ensuring efficient information retrieval. These retrieved documents will serve as important contexts for AI agent responses at each turn. The ideal count is flexible and depends on the token limits and document types.
Considerations for setting the count
- Too Few Documents/Chunks
You may miss essential information, leading to incomplete or inaccurate responses from GPT.
- Too Many Documents/Chunks
Important information may get buried under irrelevant details, making it harder for GPT to provide accurate responses.
- Context Limit
There is a limit to the amount of context that can be provided with each request. If the retrieved documents exceed this limit, SeaChat will use as many documents as can fit within the limit.
By adjusting the KB retrieval count, you can optimize the balance between depth of information and resource usage, ensuring accurate and efficient responses.
Knowledge Base Search Refinement
SeaChat now offers an advanced feature called Knowledge Base Search Refinement that allows you to further enhance the quality of retrieved information. This feature enables the AI to perform a secondary refinement on preliminary search results before generating responses.
Configuring KB Search Refinement
You can enable this feature in the Agent Information’s Advanced Settings page:
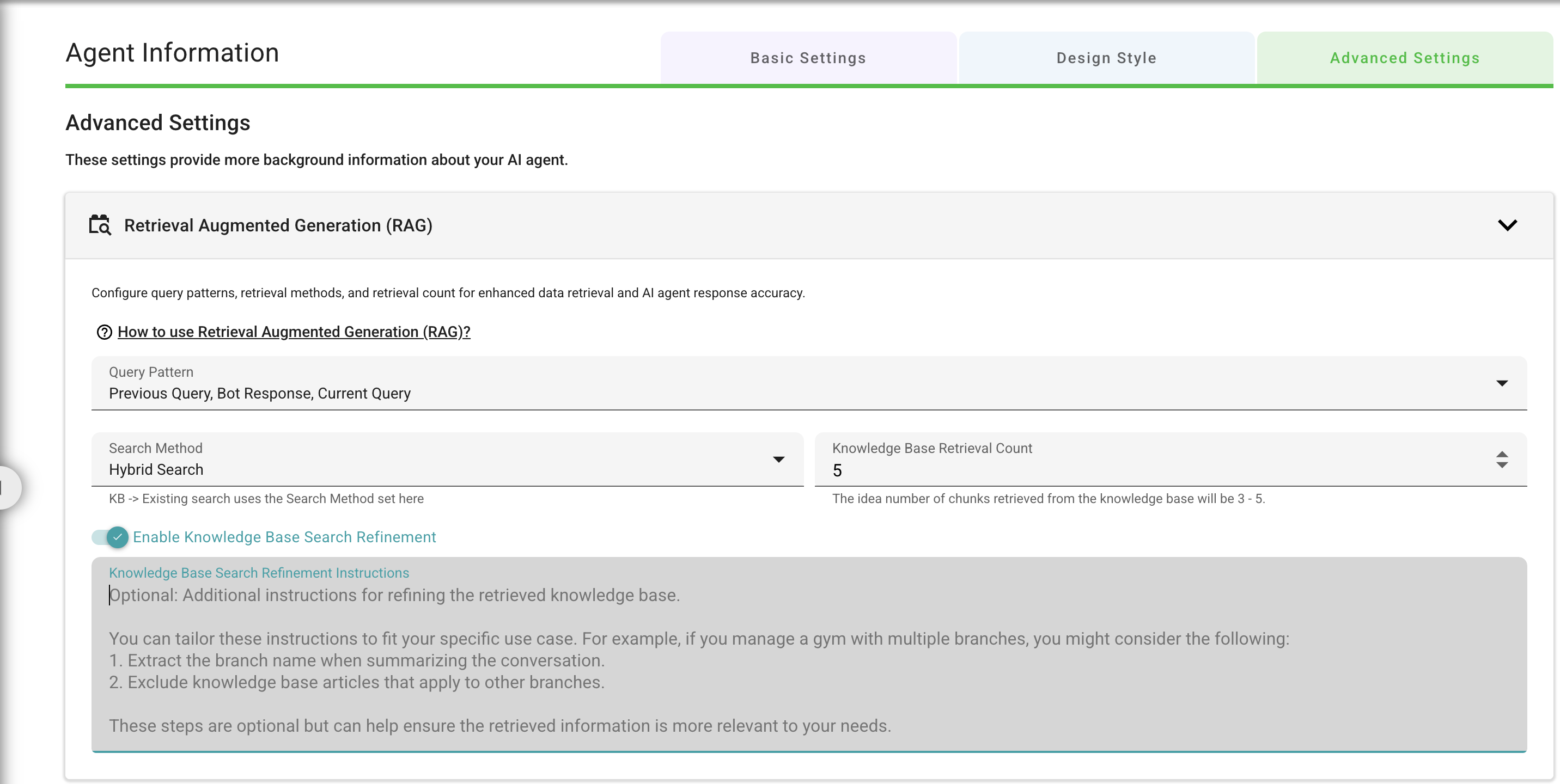
KB Search Refinement Settings in SeaChat
Optional KB Refinement Instructions
Simply enabling this feature without any additional instructions is sufficient for most use cases. The system will automatically refine search results using default optimization strategies. Custom instructions are optional but can significantly enhance performance for specific scenarios.
For more precise control over how the LLM refines search results, you can provide custom instructions in the text field. These instructions guide the AI on:
- How to evaluate document relevance
- Which types of information to prioritize
- How to handle ambiguous queries
- Special considerations for your specific knowledge domain
Example Instructions
Here are some examples of effective refinement instructions:
- “Prioritize documents containing specific product codes when the user asks about product specifications.”
- “For parking-related queries, focus on documents with location information that matches the user’s mentioned area.”
- “When handling technical support questions, prioritize the most recent documentation over older versions.”
- “For multi-part questions, ensure that documents addressing all parts of the query are included.”
- “When summarizing the conversation history, include the branch name if it can be inferred from the discussion, ensuring that it reflects the branch the user intended in the last query, even if not explicitly mentioned.”
- “When identifying relevant articles, exclude those related to branches different from the one mentioned in the summary, provided the summary specifies a branch name.”
Benefits of KB Search Refinement
Enabling this feature can significantly improve your AI agent’s performance by:
- Providing more accurate and relevant responses
- Reducing information overload in complex knowledge bases
- Handling ambiguous queries more effectively
- Improving the contextual understanding of user questions
- Delivering more concise and focused answers
By fine-tuning your KB Search Refinement settings, you can create a more intelligent and responsive AI agent that better understands and addresses your users' specific needs.
📌 Example 1: Handling Multi-Branch Knowledge with KB Search Refinement
Imagine you run a restaurant with five different branches. In your knowledge base, you’ve collected menus, service details, hours, and promotions for each branch in a spreadsheet. When users ask about a specific branch, you want your AI agent to answer with accurate, branch-specific information.
To enhance your AI agent’s performance, there are two powerful ways to improve how it processes user queries:
1. Include Branch Names in Your Knowledge Base Entries
For every cell or row in your Excel sheet, add the branch name to the content it refers to.
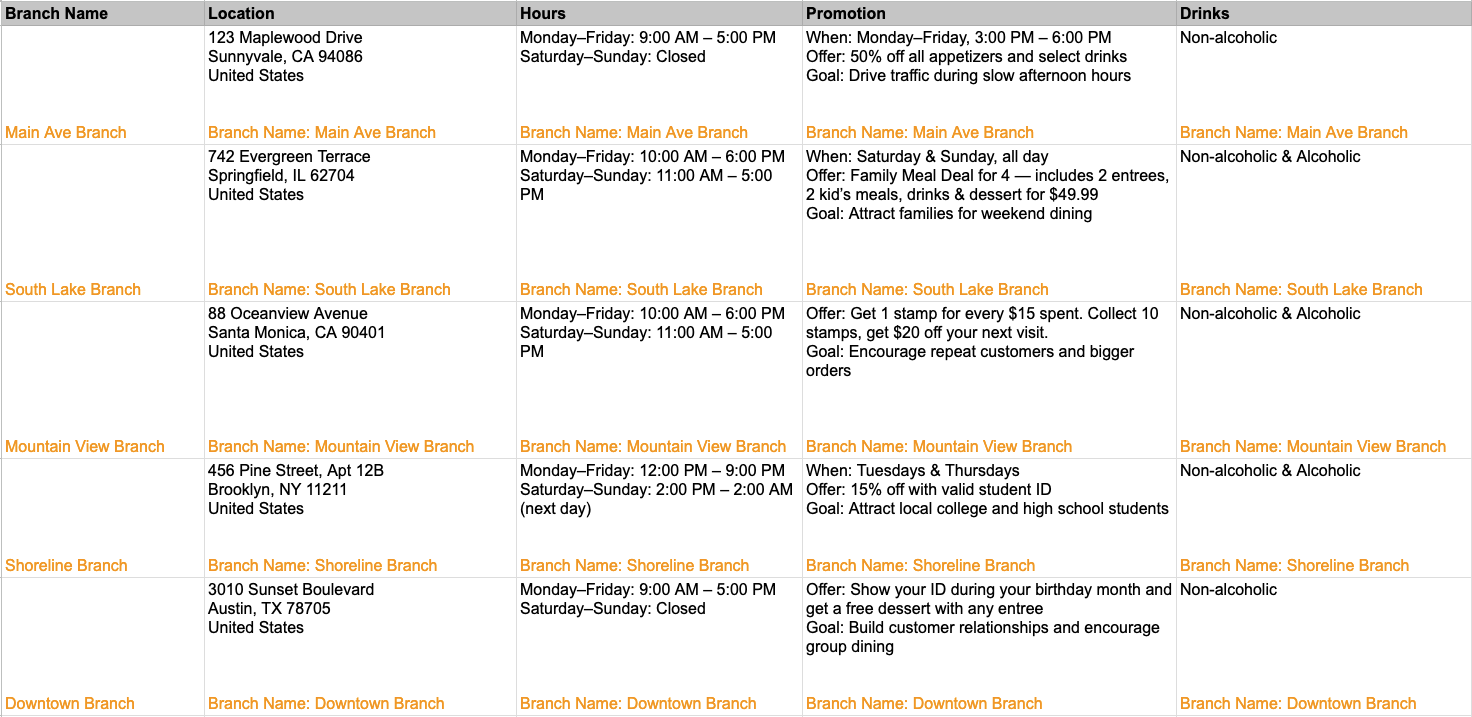
Example Spreadsheet: Multi-Branch Knowledge Base with Branch-Specific Tags
This ensures that when AI agent’s reads the knowledge base content, it understands which branch the information belongs to, improving its relevance when forming a response.
2. Upload Spreadsheet
Upload this spreadsheet to your knowledge base through the Upload Spreadsheets card. And choose this option to upload each row in the table as an individual KB document.

3. Use KB Search Refinement to Filter Irrelevant Results
Enable Knowledge Base Search Refinement feature and add refinement instructions:
Extract the branch name from user’s query.
Exclude articles or rows that refer to branches other than the one mentioned.
With these instructions, even if your initial KB search returns a mix of results from all branches, the AI agent will automatically filter out unrelated content and keep only what’s relevant to the user’s intended branch—leading to more accurate, focused, and helpful answers.
This approach is especially effective for:
- Large knowledge bases with overlapping content
- Businesses with multiple locations
- Scenarios where branch-specific accuracy is critical
By combining good KB structure (with branch names) and refinement logic, you can make your AI agent feel smarter, more precise, and more human-like.
📌 Example 2: Managing Product Information with KB Search Refinement
Imagine you manage an e-commerce platform with thousands of products. Your knowledge base contains detailed product logs including specifications, pricing, inventory status, and customer feedback across multiple spreadsheets. When customers inquire about specific products, you want your AI agent to provide accurate, product-specific information.
1. Include Product Names in Your Knowledge Base Entries
For each cell in your spreadsheet, include the product name to clearly identify the information:
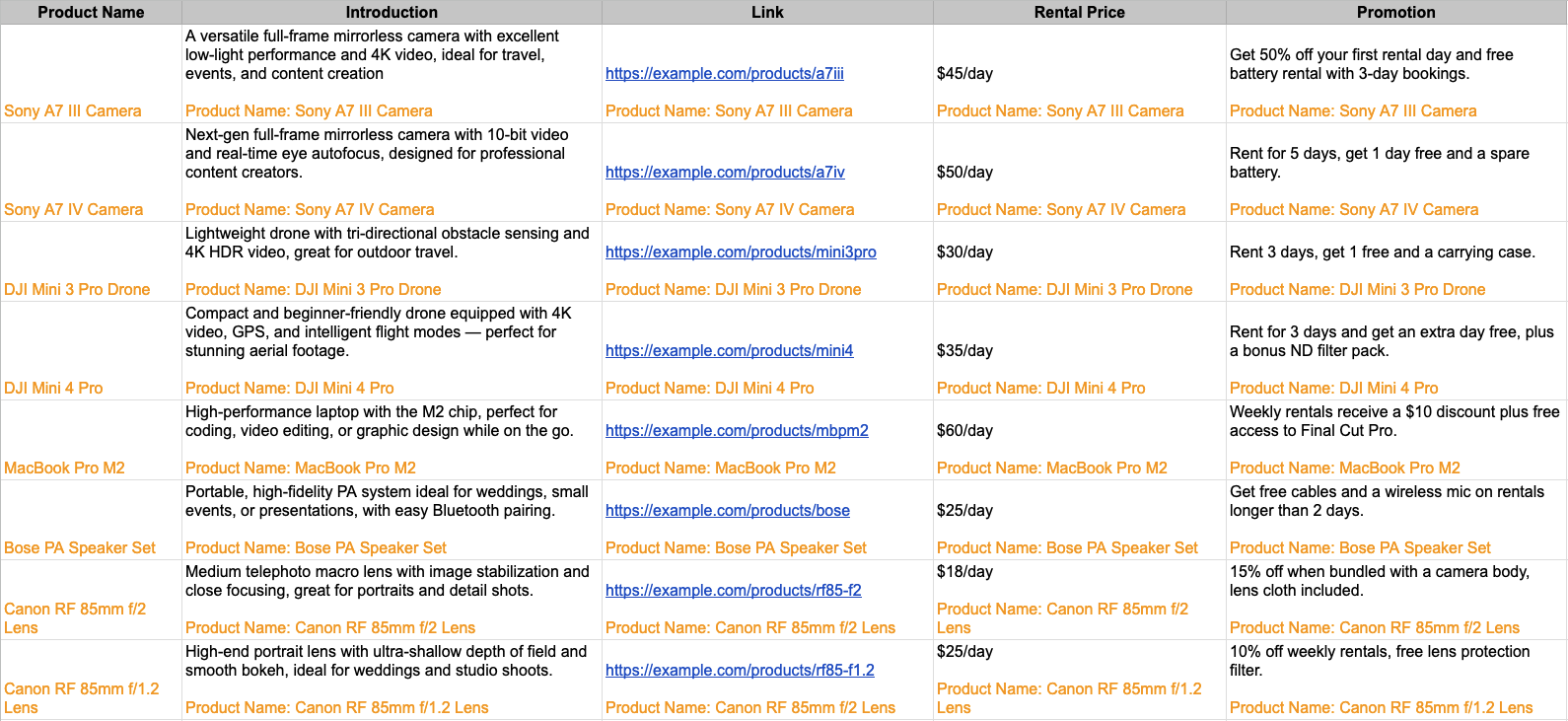
Example Spreadsheet: Product Knowledge Base with Product-Specific Tags
This structured spreadsheet ensures that when the AI agent processes the knowledge base, it can accurately associate information with specific products.
2. Upload Spreadsheet
Upload this spreadsheet to your knowledge base through the Upload Spreadsheets card. And choose this option to upload each row in the table as an individual KB document.
3. Configure KB Search Refinement Instructions
Enable Knowledge Base Search Refinement and add specific instructions:
Extract product names from the user's query.
Prioritize exact matches first, then consider product variants or related models.
Exclude information about different products unless specifically comparing features.
With these instructions, your AI agent can:
- Identify the specific product being discussed
- Focus on relevant product details
- Include related product information only when appropriate
- Maintain context across multiple queries about the same product
This approach is particularly effective for:
- Large product catalogs with similar items
- Technical support scenarios requiring precise product information
- Product comparison and recommendation queries
- Handling customer inquiries about product specifications and availability
By implementing this structure, your AI agent can efficiently navigate through extensive product information and provide accurate, contextual responses to customer queries.